Demo Day: September 2016
14 Oct 2016 | Daniel Geng and Shannon ShihOne of our main goals here at ML@B is to help students understand how to use machine learning in real-world situations. This semester, we’ve teamed up with Github, Grand Rounds, SAP, and Intuit to work on solving some of their problems through machine learning. In addition, we have members working on their own independent research projects with groups such as the International Computer Science Institute.
Just this Friday, we had our first demo day–a day where project members got to show what they were up to. Here’s a brief summary of what they had to show:
Code Synthesis
Ask any programmer, and they’ll tell you the worst part of programming is dealing with bugs. Oftentimes, software engineers will spend hours trying to fix broken pieces of code, only to find that they forgot a semicolon on the 342nd line. That’s where MIT’s Prophet comes in. Prophet is an algorithm to go through lines of code and to automatically fix bugs in the code.
But if we can fix code, does that mean we can take it one step further and begin to actually generate code? That’s what ML@B wants to know. The Code Synthesis project is focused on implementing Prophet, and then generalizing to try to begin generating code from scratch.
Active Learning
The thing with machine learning is that, most of the time, data needs to be labeled. For example, if we wanted to classify dogs and cats, we first need a very large dataset of pictures of dogs and cats, each labeled being either a dog or a cat. But labeling data can be tedious. Wouldn’t it be great if we could minimize the amount of labeled data we need?
That’s what the Active Learning Team is trying to do. They’re working in a field of machine learning called active learning, so called because algorithms here “ask” for labeled data only when they absolutely need it. Of course, there’s a trade off. The less labeled data an algorithm asks for, the more inaccurate it gets. The team’s current goal is to find a way to improve accuracy as much as possible for a certain amount of labeled data.
Github
Every day, millions of files are uploaded onto Github, a coding repository where users share code and collaborate on projects. But how do you tell what language those files are written in?
Identifying programming languages are surprisingly hard. Symbols used in one language often have different meanings in another. For example, ‘#’ in python indicates a comment, while in C it indicates a preprocessor command. Even worse, code in one language can actually contain code in different languages, such as HTML, which can contain CSS and/or Javascript.
At the moment, Github uses a giant checklist to identify unique quirks in the language. For example, if the code contains “:- module”, then it’s probably Mercury. However, most languages simply don’t have enough unique quirks for this method to be accurate enough.
The current solution the Github team at ML@B came up with is to use a machine learning algorithm called a Naïve Bayes Classifier. To optimize the program, they used Github’s checklist as a guideline for choosing the correct language rather than a hard-and-fast rule. Currently, the team is working on scraping Rosetta Code, a large repository of code in hundred of different programming languages, for data that they can use for training the program and testing its accuracy. Eventually, they will want to see if implementing other models, such as neural networks, can improve accuracy.
Grand Rounds
Grand Rounds is a health-technology company that matches patients with a specific medical problem with specialists who can solve that problem. Through analyzing a patient’s medical records, as well as a doctor’s history, Grand Rounds will recommend and actually schedule appointments with the most qualified specialists.
ML@B is helping Grand Rounds perfect their machine learning algorithms by identifying patterns in the company’s medical datasets. However, one of the biggest challenges is the size of the dataset. In it’s entirety, the dataset is more than 100GB (that’s more or less a billion pages of text) so it’s very difficult to analyze, let alone extract any data. Currently, the team is in the early stages of writing scripts to preprocess data and extract the data in an efficient manner.
Other interesting work that the team is pursuing is analyzing the dataset for medical fraud and writing scripts to compile a dictionary of medical terms.
OpenBrain
Neural networks are models based on neuroscience. They are designed to mimic how neurons fire in actual brains. And central to almost all state-of-the-art neural networks is the backpropagation (backprop) algorithm – essentially an algorithm to “update” the network and thereby “learn.” However, there’s one gigantic problem. Backprop doesn’t actually happen in real life. The problem with backprop is that it updates the whole neural network at once. In real life, when an actual brain learns something new, not every neuron in the brain changes simultaneously. Instead, individual neurons change gradually, based only on its neighboring neurons. Imagine that. We have a beautiful, mathematical model based on real biological brains, and an algorithm that couldn’t possibly happen in a real brain. This is the problem OpenBrain wants to solve. How can we develop an algorithm that is both biologically feasible, updates locally, and is still capable of learning?
Music Recommendation
Recommending music to users is a billion-dollar problem and probably one of the most visible applications of machine learning. Current state-of-the-art music recommendation algorithms suggest songs in two ways. Either by using a song’s metadata—that is, it’s composer, record label, release date, and so on—or by looking at who else listened to that song, and recommending their playlists.
However, no algorithm exists that actually uses the songs themselves to recommend music. Thus, this semester ML@B has a team dedicated a team to developing an algorithm to do just that.
As with many things in life, analyzing digital audio files is not a walk in the park. Although humans may find it easy to understand music, computers have it much harder. This is what a computer sees as music:
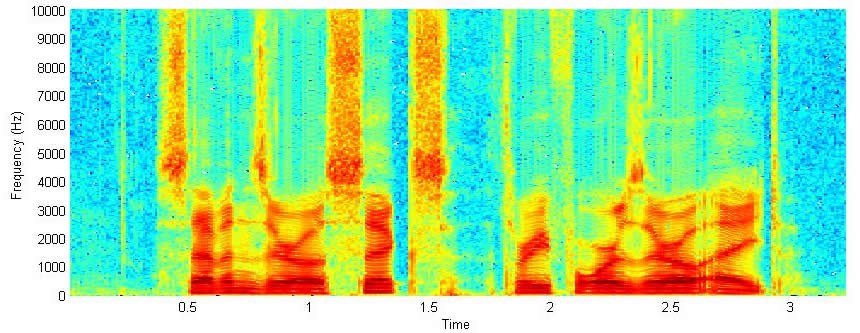
This graph, called a spectrogram, plots frequency on the vertical axis, time on the horizontal axis, and amplitude as brightness. What the team is currently working on right now is taking a spectrogram, and separating it into each of the voices in a piece of music. The idea is that by getting a separate track for bass, drums, guitar, voice and so on, analyzing a piece of a music will be much easier.
Intuit
Intuit is a company that helps small businesses and individuals with finances and taxes. The thing with taxes though, is that filling out tax returns requires tons of personal and life details. ML@B is helping the company build a program that analyzes users’ emails for important life events to help Intuit personalize its software. For example, if you got a new job, there would probably be a chain of emails between you and your new employer. By considering factors such as frequency of emails from a person, or the length of email correspondences, the will be able to program build a timeline of life events that are important to the user. This information will then help Intuit provide better financial services.
However, much of a person’s emails are either irrelevant or just plain spam. Nobody wants a 50% off deal on coffeemakers in their life’s timeline. One important problem the team is trying to solve is to categorize emails as “important” or “not-important.” The team will be investigating natural language processing and pattern recognition techniques to classify emails.
ICSI (Complex Sound)
ICSI, the International Computer Science Institute, is working with a team at ML@B to improve neural networks by using complex numbers. This research has direct application in audio recognition. This is because while sound waves can be represented as real numbers in something called the “time domain,” they can also be represented as complex numbers in the “frequency domain.” In the frequency domain, complex numbers contain a lot of information obscured in the time domain. For example, complex numbers explicitly encode the frequency and phase of a wave.
Processing phase in addition to frequency (pitch) and amplitude (loudness) allows the algorithm to extract more information from the audio, such as where it’s coming from, how the sound interacts with itself, and any changes in the sound’s ‘tone’.
To accomplish this, the team is using ‘Complex Caffe’, a novel version of Berkeley’s own deep learning framework ‘Caffe,’ which is optimized to learn and analyze sound and images. By writing new layer functions that use phase, frequency, and amplitude in their convolutional neural network, the team hopes to be able to identify ambient sounds or changes in the tone of a music more easily.
SAP
Machine learning works best when there’s a huge amount of data to work with, and one area that generates a tremendous amount of data is the stock market. Almost a century’s worth of data on hundreds of thousands of tickers is available to analyze. However, with massive amounts of data comes the complexity of having to handle it all efficiently. SAP provides a solution to this problem through the HANA Vora framework. Vora provides a platform to quickly query databases. The project team will use this to increase data throughput and quickly train a machine learning trading strategy.
In a brief review of literature, the team has discovered that researchers primarily use feedforward neural networks–the simplest type of neural network–to predict changes in stock values. However, the team believes that by utilizing recent advancements in neural network architectures, they can create more advanced, and more accurate models.
For example, a first step for the team will be to explore LSTM RNNs, a more complex type of neural network that works well on data taken over a period of time.
Time Series
Machine learning is great at identifying patterns. Thus, predicting things over time and identifying anomalies are natural extensions of its capabilities. At first glance identifying anomalies and predicting the future seem like two separate things, but they’re actually quite similar. When we flip a coin, we predict that it has a 50% chance of landing on heads and 50% of landing on tails. Similarly, when a computer predicts the future using data gathered over time, it predicts that there is an xx% chance that A will happen, a yy% chance that B will happen, and so on. So when anomalies happen, they are by definition very unlikely to happen again. Therefore, when the computer tries to predict the future, it identifies anomalies as a side effect.
Most algorithms analyze the data by considering overlapping segments of data at a time. For example, they would look at data A, B, C. Then, they move one data segment over and consider B, C, D, and then C, D, E, and so on. This is called a sliding window algorithm. However, the team is trying to make this process more efficient using their recurrent neural network, which can remember previous inputs like the sliding window algorithm. They are also displaying the probabilities of all possibilities (such as 90% chance of increase in stock price and 10% chance of decreasing), allowing the user to have a more complete picture of what will happen in the future.