
ML@B's New Projects
30 Apr 2017 | Shannon Shih, Daniel GengEvery semester, Machine Learning at Berkeley takes on new projects. Here’s the latest scoop on the newest projects we’ve taken on this semester.
Industry:
Vyrill: Sentiment Analysis
What makes or breaks a video or advertisement are the emotions it contains. ML@B’s current project with Vyrill tries to quantify this by using machine learning to estimate the positivity (or negativity) of the emotions in a video, with an emphasis on product marketing. Moreover, it also tries to identify the main subject of the video (such as the product in an unboxing video) and the reasoning behind its analysis (Did people like the video because the product being showcased was shiny? What keywords in the comments showed that the video was positive? Which part of the video was associated with the most emotion?). Beyond product evaluation, this model could also serve as a great recommendation system for movies, books, and perhaps even music. The possibilities are endless.
Unity: Deep Reinforcement Learning
Let’s face it: enemy AIs in most games are dumb and boring. This semester, Unity, the company that developed a widely used game engine, is partnering up with ML@B to develop an algorithm that, given the source code for a game, can generate an internal representation of the game which a computer can use to play the game. If all goes well, game developers can then use the model to create enemies that are not only intelligent, but learn from and adapt to your unique playstyle.
Unity: Texture De-lighting
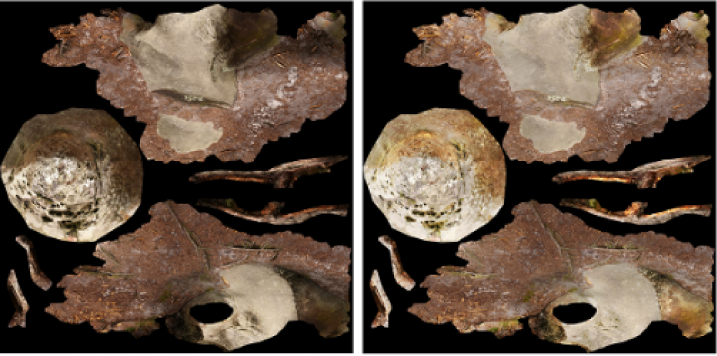
Left: The texture map of a rock; Right: the same rock, but delighted
Creating digital 3D models of real-world objects is a laborious process. Although graphic designers can now quickly create a 3D model by taking pictures of the same object at different angles, the photographs preserve lighting and shadows in the real world, so simply importing these models into a digital environment such as a game or movie will make it look odd because the lighting inside the digital environment is different from the lighting in the photos. As such, artists have to spend hours repainting the photographs so that they are “de-lighted.” In other words, they remove the highlights and shadows from the photograph so that the computer can add its own lighting. In an attempt to streamline this process, ML@B is building a model that can learn to predict how an object will look without shadows and highlights.
Investarget
Investarget is a Chinese company that connects Chinese investors with international companies and other opportunities for investment overseas. However, each of these deals must be manually evaluated by a financial analyst for its potential return, so ML@B has partnered with them to build an algorithm that can evaluate whether a company or asset is likely to return more on investment. This algorithm could potentially speed the process of locating potential assets to invest in, saving both the time of the analysts and offering more choices to investors.
Research:
SLANG
A longtime dream for computer scientists is to create a computer that can understand and react to human language. However, computers are notoriously bad at talking to humans, so ML@B is concentrating its efforts on a subset of natural language processing: narrative generation. In particular, it hopes to create a model that can generate stories with minimal user input. Stories are a particularly interesting/challenging for computers because of its qualitative, emotional, and cultural properties; it’s hard to articulate what makes a good story, yet a good story is quite recognizable and sparks an emotional response in the audience. As such, demonstrating that a computer can grasp the nuances of human language well enough to generate a good story would be a huge leap in the field of natural language processing.
Stream Computation
This project focuses on a specific but very important aspect of machine learning: data processing. Real world data is very messy, and often has to be preprocessed into the right format. This can get laborious when the amount of data gets huge. This problem gets worse when inputting a live stream of data into a machine learning model, because if the model can’t process the data fast enough, it will fall behind and its results will become out of date or useless. ML@B is hoping to streamline the entire process by creating a graph-based framework that is optimized to respond quickly moderate-sized streams of data, making it easier for programmers to write machine learning applications that can work with real-time data streams.